
Forschende in der Wirtschaftswissenschaft nutzen Befragungen und Verhaltenslabore, um ihre aus der Theorie abgeleitete Hypothesen in der realen Welt zu überprüfen. Da es sich bei diesen Datenquellen jedoch meist nur um mehr oder minder große Stichproben handelt, werden beobachtete Zusammenhänge danach unterschieden, ob sie signifikant oder nicht. Ein signifikantes Ergebnis gilt als zuverlässig nachgewiesen. Bei einem insignifikanten Ergebnis kann hingegen nicht ausgeschlossen werden, dass es rein zufällig in den Daten auftritt.
Die Signifikanz eins Ergebnisses wird mit dem sogenannten p-Wert beziffert. Er stellt die Wahrscheinlichkeit dar, dass ein geschätzter Parameter nur zufällig von 0 verschieden, also nicht signifikant ist. Ein hoher p-Wert weist auf nicht signifikantes Ergebnis, ein niedriger p-Wert auf ein signifikantes und damit vertrauenswürdiges Ergebnis hin.
Publikationsbias und p-Hacking
In der Wissenschaft hat sich eine Faustregel etabliert, wonach Ergebnisse mit einem p-Wert unter 0,05 (fünf Prozent) als ausreichend signifikant gelten. Bei ihnen ist davon auszugehen, dass das Ergebnis in mindestens 95 von 100 verschiedenen Stichproben ebenfalls von 0 verschieden wäre. Statistische Software drückt den p-Wert häufig auch in Form eines korrespondierenden z-Wertes aus. Nach diesem gängigen „Mindeststandard“ für vertrauenswürdige Studien gilt ein Ergebnis als signifikant, wenn es die dem p-Wert 0,05 entsprechende Schwelle von z=1,96 übersteigt.
Wissenschaftliche Fachzeitschriften bevorzugen für die Veröffentlichung tendenziell Studien, deren Befunde nach dieser Faustregel als statistisch signifikant bezeichnet werden. Liefert eine aufwändige Untersuchung kein solches signifikantes Ergebnis, ist damit zu rechnen, dass die Herausgeber der Fachzeitschriften eine Veröffentlichung ablehnen.
Dieser „Publikationsbias“ kann Forschende dazu verleiten, die Signifikanzschwelle mit unlauteren Mitteln zu überwinden – man spricht dabei auch von „p-Hacking“. Das wissenschaftliche Fehlverhalten kann verschiedene Formen annehmen, von der Veränderung der Testparameter und der Datenselektion bis hin zur nachträglichen Anpassung der Ausgangshypothese. Ein solches Vorgehen gilt als unethisch, lässt sich aber im Einzelfall in der Praxis schwer nachweisen.
IZA-Netzwerkmitglied Abel Brodeur von der Universität Ottawa widmet sich dieser Problematik gemeinsam mit verschiedenen Koautoren seit vielen Jahren. Bereits 2013 hat er in seiner preisgekrönten Studie „Star Wars: The Empirics Strike Back“ Belege für die verbreitete Praxis des p-Hacking geliefert. Die Anreize dafür sind enorm: Die Wahrscheinlichkeit der Veröffentlichung einer wissenschaftlichen Arbeit ist fast fünfmal so groß, wenn das Ergebnis die Signifikanzschwelle überschreitet.
Crowdsourcing zur Gewinnung von Forschungsdaten
Seine damals entwickelte Analysemethode nutzt Brodeur gemeinsam mit Nikolai Cook und Anthony Heyes auch in einem aktuellen IZA-Forschungspapier, in dem es um wissenschaftliche Veröffentlichungen geht, deren Daten mithilfe der Crowdsourcing-Plattform Amazon Mechanical Turk (MTurk) erhoben wurden.
Bei der Plattform handelt es sich um eine Art Jobbörse für einmalige Aufträge, die sich aus der Ferne online bearbeiten lassen. Der Dienst erfreut sich auch für Umfragen und als Verhaltenslabor in den Wirtschaftswissenschaften und verwandten Disziplinen wachsender Beliebtheit, da sich darüber große Stichproben zu geringen Kosten generieren lassen. Inzwischen wird jedoch die Qualität der Studien mit MTurk-Daten zunehmend in Frage gestellt.
Auswertung von 23.000 Hypothesentests
Brodeur und Koautoren wollten es genauer wissen. Sie stellten über 1.000 Studien auf den Prüfstand, die seit 2010 in renommierten Fachjournalen erschienen sind und insgesamt fast 23.000 Hypothesentests auf Basis von MTurk-Daten umfassen. Welche Signifikanzniveaus darin wie häufig vertreten sind, zeigt das folgende Schaubild anhand des z-Werts (je größer der z-Wert, desto signifikanter das Ergebnis).
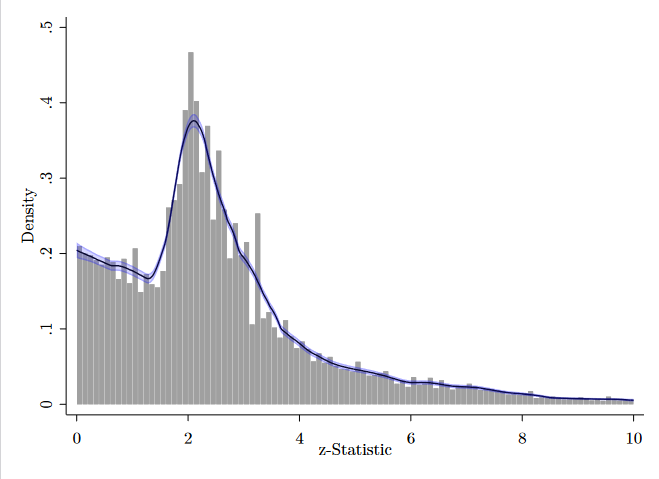
Gäbe es weder einen Publikationsbias noch p-Hacking, sollten die z-Werte einer monoton fallenden Verteilung folgen. Sehr insignifikante Ergebnisse sind am wahrscheinlichsten, sollten also am häufigsten auftreten. Etwas signifikantere Ergebnisse sollten seltener auftreten, hoch signifikante Befunde am seltensten. Ein manipulationsfreier Publikationsprozess sollte also keine Häufungen bei höheren Signifikanzniveaus aufweisen.
Was jedoch direkt auffällt, ist eine starke Häufung gerade oberhalb des Mindeststandards von z=1,96, der sich als Faustregel etabliert hat und dem fünfprozentigen Signifikanzniveau entspricht. Links, also gerade unterhalb des Mindeststandards, tut sich stattdessen eine Lücke auf – ein wichtiges Indiz für Manipulation. Diese Lücke spricht dafür, dass vielfach auf p-Hacking zurückgegriffen wurde, um diese Schwelle „so gerade eben“ zu überwinden, oder aber dass Herausgeber der Fachzeitschriften Studien mit Ergebnissen knapp oberhalb dieser Schwelle präferieren.
Unterschiede zwischen den Disziplinen
Das Ausmaß des Problems unterscheidet sich deutlich zwischen den verschiedenen wissenschaftlichen Disziplinen. Wie sich an den Kurvenformen in der folgenden Abbildung ablesen lässt, ist p-Hacking etwa in der Marketingforschung vergleichsweise stark verbreitet, während Volkswirtschaftslehre und Finanzwissenschaft kaum betroffen sind.
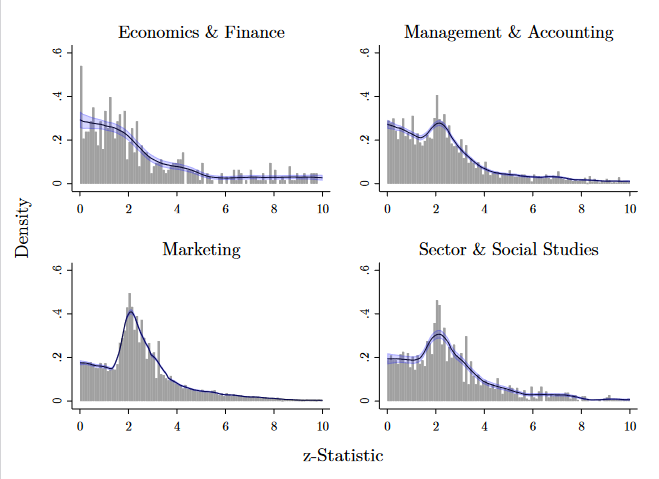
Verwendung zu kleiner Stichproben
Darüber hinaus stellen die Forscher eine außergewöhnlich geringe Stichprobengröße fest (der Medianwert liegt bei 249), obwohl jeder zusätzliche Datenpunkt bei den MTurk-Erhebungen im Schnitt kaum mehr als einen Dollar kostet, oft sogar deutlich weniger.
Insgesamt sehen die Autoren dadurch die Glaubwürdigkeit eines Großteils der betreffenden Studien beschädigt. „Würde man versuchen, eine zufällig ausgewählte Studie aus unserer Stichprobe zu replizieren, wird man mit hoher Wahrscheinlichkeit scheitern“, sagt Brodeur.
Eine positive Botschaft haben die Autoren aber dennoch: Die dargestellten Probleme liegen offenkundig nicht in der Datenerhebung, sondern im Umgang mit den erhobenen Daten. Grundsätzlich spreche also nichts dagegen, MTurk oder ähnliche Plattformen weiterhin zu nutzen, solange ausreichend große Stichproben erhoben und wissenschaftliche Standards eingehalten werden.
Auch die Einreichung sogenannter „Pre-Analysis Plans“, in denen die Vorgehensweise bei der Datenanalyse vorab festgelegt wird, kann p-Hacking entgegenwirken, wie ein weiteres IZA-Forschungspapier von Brodeur und Koautoren zeigt.