
Children’s beliefs about their abilities or place in society are known to be shaped at a young age by race- and gender-based messages such as those implicitly conveyed in educational materials. As a result, it is vital that we understand how race and gender are portrayed in the content we present to our children.
A recent IZA discussion paper (forthcoming in the Quarterly Journal of Economics) uses AI tools that convert images into data on representation of skin colors, race, gender, and age in a century of influential children’s books. This work contributes to our knowledge of what messages are conveyed in the content we use to teach and entertain our children. It also expands the set of tools available for social scientists to measure representation in a variety of contexts.
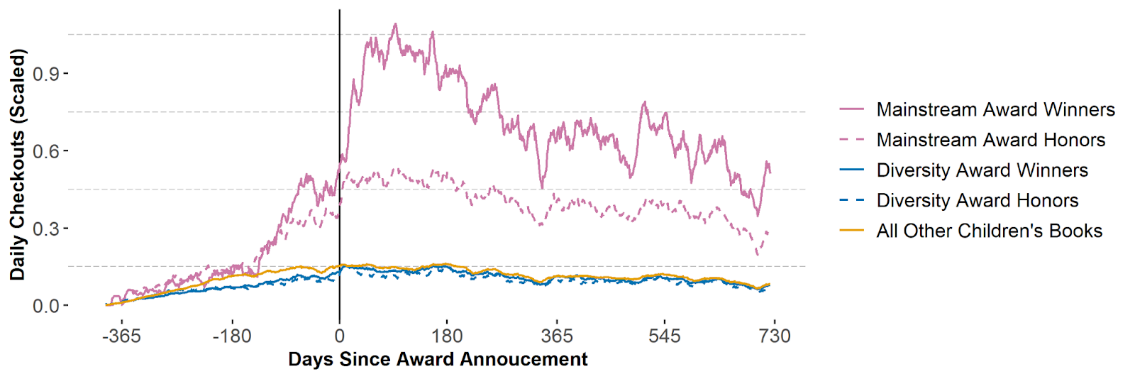
The authors of this study focus on award winning children’s books which are divided into two collections: “Mainstream” books considered to be of high literary or artistic value, and “Diversity” books selected because of how they center experiences of specific underrepresented identity groups in addition to their high literary value. They find that library checkouts for books in the Mainstream collection increase dramatically after receiving an award, implying that children are more likely to be exposed to the content of these particular stories.
The natural first step when measuring representation in images is to apply face detection to identify all depicted faces. However, off-the-shelf face detection models have a significant drawback; while off-the-shelf methods are an excellent way to detect faces in photographs, they perform poorly when applied to illustrations. Since many of the images found in content targeted towards children contain illustrations, this presented a problem. To overcome this, the authors construct a novel training dataset to build a model which can better detect faces in both photographs and illustrations. This model allowed them to detect 2.5 times more faces in their sample of children’s books than they would have using off-the-shelf face detection methods.
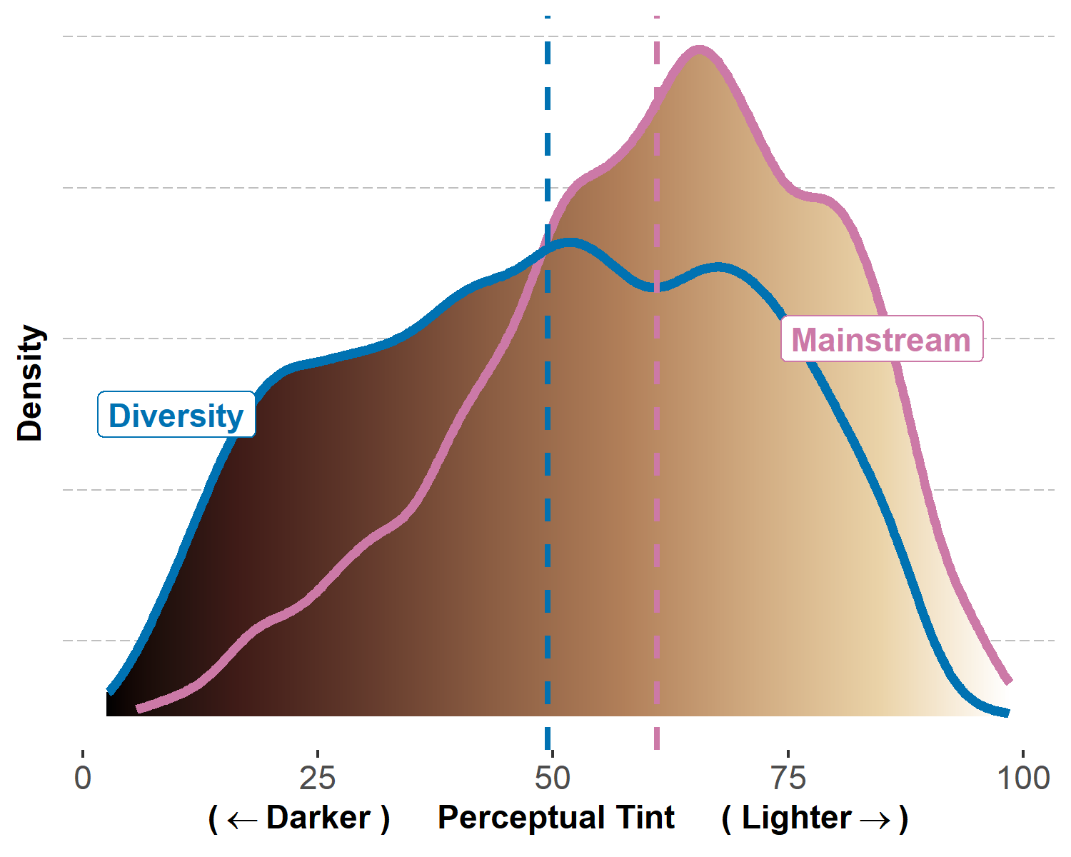
Applying their face detection model along with other computer vision tools such as skin segmentation, the authors find that faces depicted in the Mainstream collection are lighter on average than faces depicted in the Diversity collection. This is true even when conditioning on a face’s predicted race (e.g. faces predicted to be Black are lighter on average in the Mainstream collection than faces predicted to be Black in the Diversity collection). Perceptual Tint is used as a measure of how light or dark a skin color is on a scale of 0-100.
Another key finding is that relative to their growing share of the U.S. population, Black and Latinx people are underrepresented in these same books, while White males are overrepresented. Female representation in the text of these stories has grown from about 25% of all gendered terms and names to almost parity in recent years. However, even though females are increasingly present in the text of these stories, they appear less often in text than in images, suggesting greater symbolic inclusion in pictures than substantive inclusion in stories.
In an effort to understand the determinants of demand for representation in children’s books, the authors use data on children’s book purchases to understand who is purchasing books with different levels of representation. They find that people are more likely to purchase children’s books which contain representations of their own identities or the identities of their children. For example, purchasers who identify as Black or as Latinx are more likely to buy books that contain pictured characters with darker skin color, on average, than purchasers who identify as White. They also find that on average, purchasers who have a son purchase books with a lower percentage of female names, as compared to purchasers that have no children.
By merging the location of children’s book purchasers to data on local beliefs from the Cooperative Election Study, the authors show that a greater number of purchases of books from the Diversity collection is associated with a smaller proportion of individuals who believe that undocumented immigrants should be deported and a larger proportion of individuals who believe that White people in the U.S. have certain advantages because of the color of their skin.
Overall, this study uses AI tools to reveal enduring inequality in representation of skin colors, race, gender, and age within influential children’s books. It also establishes evidence that demand for representation in children’s books is related to consumers’ identities as well as their personal and political beliefs. These results suggest how the demand for representation may be a channel through which beliefs about race and gender could propagate across generations through the messages contained in the books parents purchase for their children. The findings in this study generate hypotheses that can motivate and inform subsequent research on the causes and consequences of representation in children’s books.